
重点是 Dispatch 和 Resolve 两个算法。
动机
过程间分析的动机主要还是为了处理方法调用(method calls)带来的分析问题。在做纯过程内分析时,处理方法调用问题会采用最保守的假设:方法调用可以做任何事情,传来的值也可以是任何一个值。比如下面这个常量传播的例子就无法被过程内分析解决(显然保守假设会使得所有的变量都被识别为 NAC):
1 | void foo() { |
可以看到,纯过程内分析会损失许多 分析精度 ,需要引入过程间分析。过程间分析的基本思想是将数据流信息沿着过程间的控制流边(即控制流图中的 call 和 return 边)传播,由此可知,做过程间分析需要的一个必要信息就是调用图 Call Graph,告诉我们程序中的调用信息。
Call Graph Construction(以 CHA 为例)
调用图的定义非常简单,就是从调用点指向其目标 方法 (被调用者,称作 callees,不仅仅是函数调用)的调用边的集合。它表征了非常重要的程序信息,不仅可以用于过程间分析,还可以用于程序优化、测试、debugging 等。
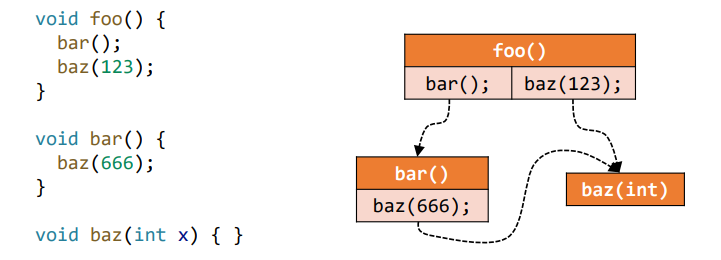
针对形如 Java 的面向对象编程语言(OOPLs),调用图的构造有多种算法,以下四个比较具有代表性:
- 类层次分析(Class hierarchy analysis, CHA,速度最快)
- 快速类型分析(Rapid type analysis, RTA)
- 变量类型分析(Variable type analysis, VTA)
- 指针分析(Pointer analysis, k-CFA,精度最高)
本章的讨论重点在于类层次分析 CHA。
Java 中的调用(Invocations)
Java 中的调用主要分为 Static call, Special call, Virtual call 三大类(Java 8 以后还引入了 invokedynamic,主要是用来实现动态类型语言的,暂时不在讨论范围内):
| Static call | Special call | Virtual call | |
|---|---|---|---|
| 对应的虚拟机指令 | invokestatic | invokespecial | invokeinterface, invokevirtual |
| 是否有接收对象 | × | √ | √ |
| 目标方法(调用的对象) | 静态方法(static methods) | 构造函数(constructors) 私有实例方法(private instance methods) 父类的实例方法(superclass instance methods) |
其他实例方法 |
| 调用对象个数 | 1 | 1 | ≥ 1(用于实现面向对象“多态”的特性,因此运行时才能确定接收对象的具体类型) |
| Determinacy | Compile-time | Compile-time | Run-time |
因此可以看出,为 OOPLs 构造调用图的关键就在于如何处理虚拟调用(Virtual call)。
Method Dispatch of Virtual Calls
对于每个 virtual call,在动态的运行时中要对其进行 resolve(解它的目标方法),这个过程就叫做 method dispatch,涉及到以下两个要素:
- 接收对象的具体类型(例如
o.foo()中 o 指向对象的类型),用 c 指代 - 调用点的方法签名(例如
o.foo()中的 foo),用 m 指代
下面展开 签名 的定义。一个签名(signature)扮演的角色是一个方法的标识符(identifier),也即通过一个签名可以唯一地确定一个方法:
Signature = class type + method name + descriptor
- descriptor = return type + parameter types
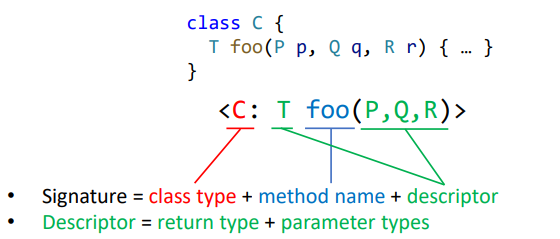
在实际的程序书写中, <C: T foo(P, Q, R)> 一般都被简化表示为 C.foo(P, Q, R) 了。
基于上面提到的 c、m 两个要素,我们定义一个函数 Dispatch(c, m) 来模拟运行时中执行 method dispatch 的过程。

用下面的程序举例而言:
1 | class A { |
根据 Dispatch 函数的定义,可以得到 Dispatch(B, A.foo()) = A.foo(),Dispatch(C, A.foo()) = C.foo() 的正确结果。
类层次分析 CHA
- 需要:整个程序的类层次结构信息(整个程序的继承结构)
- 基于调用点处接收变量的声明类型(declared type)来对相应的 virtual call 做 resolve 操作
以如下的程序举例:
1 | A a = ... |
CHA 假设接收变量 a 可以指向 A 类或者 A 的所有父类的对象。因此,解目标方法的过程就是不断对 A 类的类层次结构做 look up 的过程。CHA 的算法基础是用以解算调用点 cs 处可能的目标方法的函数 Resolve(cs):

CHA 的特点:
-
优点:快
- 只考虑调用点处接收变量的声明类型,以及它的继承层次,忽略了数据流和控制流的信息
-
缺点:不够精确
-
很容易引入伪目标方法
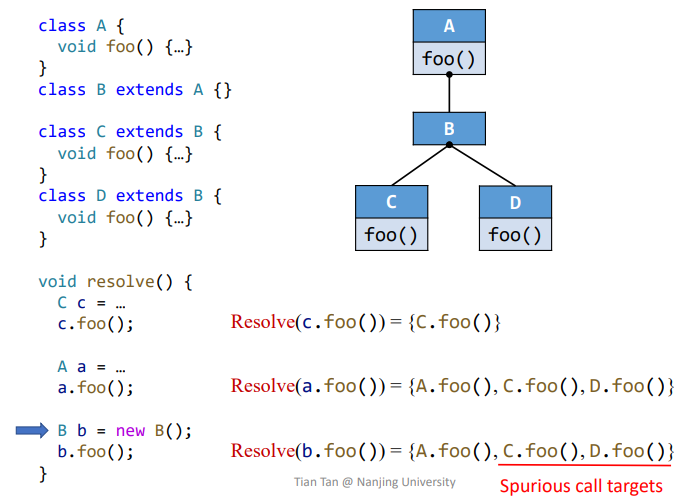
(执行的是算法的第三步 virtual call 部分,在解算父类 A 的目标方法时把 C 和 D 也算进去了)
-
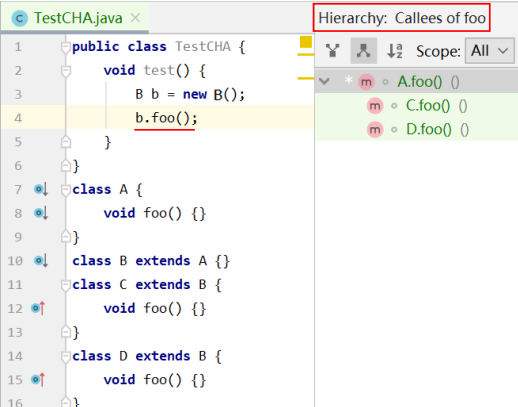
CHA 一般在 IDE 中使用,比如 IntelliJ IDEA 的侧边栏处就可以查看可能的目标方法。
使用 CHA 构造调用图
- 从入口方法开始(关注 main 方法)
- 针对每个可达的方法 m,对 m 中所有的调用点 cs 都执行 CHA 以解算可能的目标方法
- 重复执行上面的步骤,直到没有新的方法被发现

过程间控制流图 ICFG
如果说 CFG 表征了一个独立方法内部的结构,那么 ICFG 就表征了整个程序的结构,利用 ICFG,我们就可以执行过程间分析。ICFG 的结构很简单,由每个独立方法的 CFG 图和 call & return 边构成,即 ICFG = CFGs + call & return edges。
- call 边:从调用点指向被调用者(即那些调用点的 callees)的入口结点
- return 边:从被调用者的出口结点指向其调用点(即返回点,return sites)后面的语句
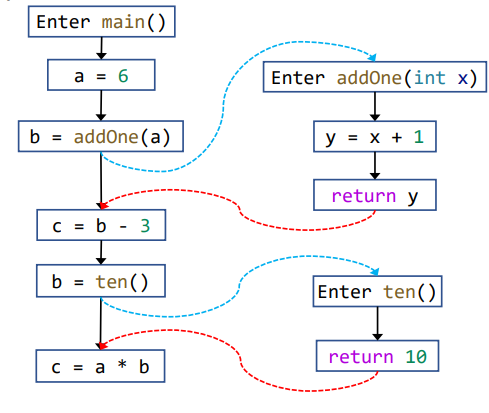
一般来说,从调用点指向其后面语句的那条 CFG 边(比如从 b = addOne(a) 指向 c = b - 3 )被称为 call-to-return 边,其余 CFG 边被称为 normal 边。
过程间数据流分析
分析 ICFG 和 CFG 的不同之处,可以得出在进行过程间数据流分析、构造转移函数时,除了构造节点的转移函数,还要构造边的转移函数(Node transfer + Edge transfer)。边转移分为以下两种:
- call edge transfer:将数据流从调用点转移到被调用者的入口结点,传递的是参数值
- return edge transfer:将数据流从被调用者的出口结点转移到返回点,传递的是返回值
进行过程间分析时,Node transfer 的过程与过程内分析相同,除了要对 call nodes 特殊处理,将其当成一个独立的函数。比如在做常量传播时,将 LHS 变量(返回值)的处理留给边转移函数进行处理,而不是保守地处理为 NAC:
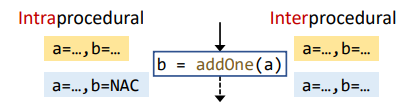
此时,前面提到的 call-to-return 边会发挥它的作用。在 call-to-return 边上,我们会 kill 掉调用点处 LHS 变量的值 ,即该变量的值由沿着 return 边返回的结果决定,否则会导致结果不精确。可以看到这条特殊的边允许分析在 ICFG 上传播方法内部的本地数据流,相当于在这条边上会合并本地数据流和边转移函数返回的来自其他方法的数据流。如果没有这样的边,我们必须在方法间传播本地数据流,这是非常低效的。
LHS:赋值操作的目标
RHS:赋值操作的源头
这一节的编程作业也很好做,直接翻译算法伪代码即可。